ddd落地
如何知道你的模型是贫血的呢?可以看一下你代码中是否有以下的几个特征:
- **有大量的XxxDO对象:**这里DO虽然有时候代表了Domain Object,但实际上仅仅是数据库表结构的映射,里面没有包含(或包含了很少的)业务逻辑;
- **服务和Controller里有大量的业务逻辑:**比如校验逻辑、计算逻辑、格式转化逻辑、对象关系逻辑、数据存储逻辑等;
- 大量的Utils工具类等。
劣势
- **数据库思维:**从有了数据库的那一天起,开发人员的思考方式就逐渐从“写业务逻辑“转变为了”写数据库逻辑”,也就是我们经常说的在写CRUD代码。
- **贫血模型“简单”:**贫血模型的优势在于“简单”,仅仅是对数据库表的字段映射,所以可以从前到后用统一格式串通。这里简单打了引号,是因为它只是表面上的简单,实际上当未来有模型变更时,你会发现其实并不简单,每次变更都是非常复杂的事情
- **脚本思维:**很多常见的代码都属于“脚本”或“胶水代码”,也就是流程式代码。脚本代码的好处就是比较容易理解,但长久来看缺乏健壮性,维护成本会越来越高。
但是可能最核心的原因在于,实际上我们在日常开发中,混淆了两个概念:
- **数据模型(Data Model):**指业务数据该�如何持久化,以及数据之间的关系,也就是传统的ER模型;
- **业务模型/领域模型(Domain Model):**指业务逻辑中,相关联的数据该如何联动。
所以,解决这个问题的根本方案,就是要在代码里严格区分Data Model和Domain Model,具体的规范会在后文详细描述。在真实代码结构中,Data Model和 Domain Model实际上会分别在不同的层里,Data Model只存在于数据层,而Domain Model在领域层,而链接了这两层的关键对象,就是Repository。
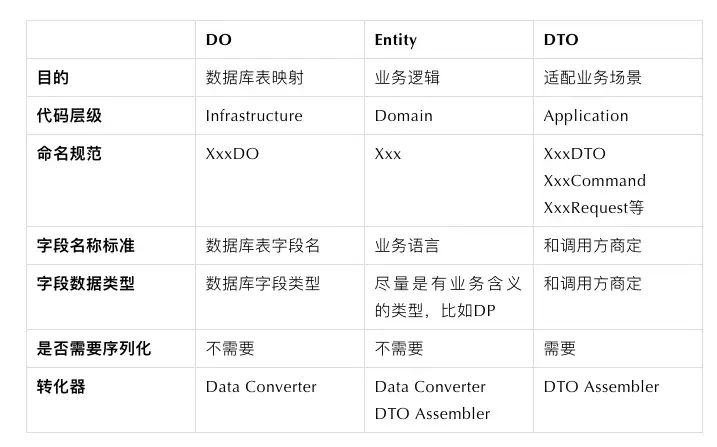
实体类(Entity)
创建即一致
使用Factory模式来降低调用方复杂度
尽量避免public setter
通过聚合根保证主子实体的一致性
主实体就需要起到聚��合根的作用,即:
- 子实体不能单独存在,只能通过聚合根的方法获取到。任何外部的对象都不能直接保留子实体的引用
- 子实体没有独立的Repository,不可以单独保存和取出,必须要通过聚合根的Repository实例化
- 子实体可以单独修改自身状态,但是多个子实体之间的状态一致性需要聚合根来保障
常见的电商域中聚合的案例如主子订单模型、商品/SKU模型、跨子订单优惠、跨店优惠模型等。很多聚合根和Repository的设计规范在我前面一篇关于Repository的文章中已经详细解释过,可以拿来参考。
不可以强依赖其他聚合根实体或领域服务
一个实体的原则是高内聚、低耦合,即一个实体类不能直接在内部直接依赖一个外部的实体或服务。这个原则和绝大多数ORM框架都有比较严重的冲突,所以是一个在开发过程中需要特别注意的。这个原则的必要原因包括:对外部对象的依赖性会直接导致实体无法被单测;以及一个实体无法保证外部实体变更后不会影响本实体的一致性和正确性。
所以,正确的对外部依赖的方法有两种:
- 只保存外部实体的ID:这里我再次强烈建议使用强类型的ID对象,而不是Long型ID。强类型的ID对象不单单能自我包含验证代码,保证ID值的正确性,同时还能确保各种入参不会因为参数顺序变化而出bug。具体可以参考我的Domain Primitive文章。
- 针对于“无副作用”的外部依赖,通过方法入参的方式传入。比如上文中的equip(Weapon,EquipmentService)方法。
如果方法对外部依赖有副作用,不能通过方法入参的方式,只能通过Domain Service解决,见下文。
任何实体的行为只能直接影响到本实体(和其子实体)
这个原则更多是一个确保代码可读性、可理解的原则,即任何实体的行为不能有“直接”的”副作用“,即直接修改其他的实体类。这么做的好处是代码读下来不会产生意外。
另一个遵守的原因是可以降低未知的变更的风险。在一个系统里一个实体对象的所有变更操作应该都是预期内的,如果一个实体能随意被外部直接修改的话,会增加代码bug的风险
领域服务(Domain Service)
单对象策略型
这种领域对象主要面向的是单个实体对象的变更,但涉及到多个领域对象或外部依赖的一些规则。在上文中,EquipmentService即为此类:
- 变更的对象是Player的参数
- 读取的是Player和Weapon的数据,可能还包括从外部读取一些数据
在这种类型下,实体应该通过方法入参的方式传入这种领域服务,然后通过Double Dispatch来反转调用领域服务的方法,比如:
Player.equip(Weapon, EquipmentService) {
EquipmentService.canEquip(this, Weapon);
}
为什么这种情况下不能先调用领域服务,再调用实体对象的方法,从而减少实体对领域服务的入参型依赖呢?比如,下面这个方法是错误的:
boolean canEquip = EquipmentService.canEquip(Player, Weapon);
if (canEquip) {
Player.equip(Weapon); // ❌,这种方法不可行,因为这个方法有不一致的可能性
}
其错误的主要原因是缺少了领域服务入参会导致方法有可能产生不一致的情况。
跨对象事务型
当一个行为会直接修改多个实体时,不能再通过单一实体的方法作处理,而必须直接使用领域服务的方法来做操作。在这里,领域服务更多的起到了跨对象事务的作用,确保多个实体的变更之间是有一致性的。
在上文里,虽然以下的代码虽然可以跑到通,但是是不建议的:
public class Player {
void attack(Monster, CombatService) {
CombatService.performAttack(this, Monster); // ❌,不要这么写,会导致副作用
}
}
而我们真实调用应该直接调用CombatService的方法:
public void test() {
//...
combatService.performAttack(mage, orc);
}
这个原则也映射了4.1.5 的原则,即Player.attack会直接影响到Monster,但这个调用Monster又没有感知。
策略对象(Domain Policy)
Policy或者Strategy设计模式是一个通用的设计模式,但是在DDD架构中会经常出现,其核心就是封装领域规则。
一个Policy是一个无状态的单例对象,通常需要至少2个方法:canApply 和 一个业务方法。其中,canApply方法用来判断一个Policy是否适用于当前的上下文,如果适用则调用方会去触发业务方法。通常,为了降低一个Policy的可测试性和复杂度,Policy不应该直接操作对象,而是通过返回计算后的值,在Domain Service里对对象进行操作。
在上文案例里,DamagePolicy只负责计算应该受到的伤害,而不是直接对Monster造成伤害。这样除了可测试外,还为未来的多Policy叠加计算做了准备。
领域事件实现
和消息队列中间件不同的是,领域事件通常是立即执行的、在同一个进程内、可能是同步或异步。我们可以通过一个EventBus来实现进程内的通知机制,简单实现如下:
// 实现者:瑜进 2019/11/28
public class EventBus {
// 注册器
@Getter
private final EventRegistry invokerRegistry = new EventRegistry(this);
// 事件分发器
private final EventDispatcher dispatcher = new EventDispatcher(ExecutorFactory.getDirectExecutor());
// 异步事件分发器
private final EventDispatcher asyncDispatcher = new EventDispatcher(ExecutorFactory.getThreadPoolExecutor());
// 事件分发
public boolean dispatch(Event event) {
return dispatch(event, dispatcher);
}
// 异步事件分发
public boolean dispatchAsync(Event event) {
return dispatch(event, asyncDispatcher);
}
// 内部事件分发
private boolean dispatch(Event event, EventDispatcher dispatcher) {
checkEvent(event);
// 1.获取事件数组
Set<Invoker> invokers = invokerRegistry.getInvokers(event);
// 2.一个事件可以被监听N次,不关心调用结果
dispatcher.dispatch(event, invokers);
return true;
}
// 事件总线注册
public void register(Object listener) {
if (listener == null) {
throw new IllegalArgumentException("listener can not be null!");
}
invokerRegistry.register(listener);
}
private void checkEvent(Event event) {
if (event == null) {
throw new IllegalArgumentException("event");
}
if (!(event instanceof Event)) {
throw new IllegalArgumentException("Event type must by " + Event.class);
}
}
}
调用方式:
public class LevelUpEvent implements Event {
private Player player;
}
public class LevelUpHandler {
public void handle(Player player);
}
public class Player {
public void receiveExp(int value) {
this.exp += value;
if (this.exp >= 100) {
LevelUpEvent event = new LevelUpEvent(this);
EventBus.dispatch(event);
this.exp = 0;
}
}
}
@Test
public void test() {
EventBus.register(new LevelUpHandler());
player.setLevel(1);
player.receiveExp(100);
assertThat(player.getLevel()).equals(2);
}
总结
在真实的业务逻辑里,我们的领域模型或多或少的都有一定的“特殊性”,如果100%的要符合DDD规范可能会比较累,所以最主要的是梳理一个对象行为的影响面,然后作出设计决策,即:
- 是仅影响单一对象还是多个对象,
- 规则未来的拓展性、灵活性,
- 性能要求,
- 副作用的处理,等等
Application层的组成部分
Application层的几个核心类:
- ApplicationService应用服务:最核心的类,负责业务流程的编排,但本身不负责任何业务逻辑
- DTO Assembler:负责将内部领域模型转化为可对外的DTO
- Command、Query、Event对象:作为ApplicationService的入参
- 返回的DTO:作为ApplicationService的出参
Application层最核心的对象是ApplicationService,它的核心功能是承接“业务流程“。但是在讲ApplicationService的规范之前,必须要先重点的讲几个特殊类型的对象,即Command、Query和Event。
- Command指令:指调用方明确想让系统操作的指令,其预期是对一个系统有影响,也就是写操作。通常来讲指令需要有一个明确的返回值(如同步的操作结果,或异步的指令已经被接受)。
- Query查询:指调用方明确想查询的东西,包括查询参数、过滤、分页等条件,其预期是对一个系统的数据完全不影响的,也就是只读操作。
- Event事件:指一件已经发生过的既有事实,需要系统根据这个事实作出改变或者响应的,通常事件处理都会有一定的写操作。事件处理器不会有返回值。这里需要注意一下的是,Application层的Event概念和Domain层的DomainEvent是类似的概念,但不一定是同一回事,这里的Event更多是外部一种通知机制而已。
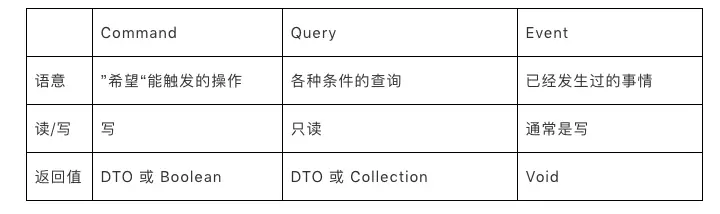
- CQE的规范
所以在Application层的接口里,强力建议的一个规范是:
规范:ApplicationService的接口入参只能是一个Command、Query或Event对象,CQE对象需要能代表当前方法的语意。唯一可以的例外是根据单一ID查询的情况,可以省略掉一个Query对象的创建
按照上面的规范,实现案例是:
public interface CheckoutService {
OrderDTO checkout(@Valid CheckoutCommand cmd);
List<OrderDTO> query(OrderQuery query);
OrderDTO getOrder(Long orderId); // 注意单一ID查询可以不用Query
}
@Data
public class CheckoutCommand {
private Long userId;
private Long itemId;
private Integer quantity;
}
@Data
public class OrderQuery {
private Long sellerId;
private Long itemId;
private int currentPage;
private int pageSize;
}
这个规范的好处是:提升了接口的稳定性、降低低级的重复,并且让接口入参更加语意化
ApplicationService应该永远返回DTO而不是Entity
- 构建领域边界:ApplicationService的入参是CQE对象,出参是DTO,这些基本上都属于简单的POJO,来确保Application层的内外互相不影响。
- 降低规则依赖:Entity里面通常会包含业务规则,如果ApplicationService返回Entity,则会导致调用方直接依赖业务规则。如果内部规则变更可能直接影响到外部。
- 通过DTO组合降低成本:Entity是有限的,DTO可以是多个Entity、VO的自由组合,一次性封装成复杂DTO,或者有选择的抽取部分参数封装成DTO可以降低对外的成本。
Interface层:
- 职责:主要负责承接网络协议的转化、Session管理等
- 接口数量:避免所谓的统一API,不必人为限制接口类的数量,每个/每类业务对应一套接口即可,接口参数应该符合业务需求,避免大而全的入参
- 接口出参:统一返回Result
- 异常处理:应该捕捉所有异常,避免异常信息的泄漏。可以通过AOP统一处理,避免代码里有大量重复代码。
Application层:
- 入参:具像化Command、Query、Event对象作为ApplicationService的入参,唯一可以的例外是单ID查询的场景。
- CQE的语意化:CQE对象有语意,不同用例之间语意不同,即使参数一样也要避免复用。
- 入参校验:基础校验通过Bean Validation api解决。Spring Validation自带Validation的AOP,也可以自己写AOP。
- 出参:统一返回DTO,而不是Entity或DO。
- DTO转化:用DTO Assembler负责Entity/VO到DTO的转化。
- 异常处理:不统一捕捉异常,可以随意抛异常。