实验一:用transformers本地部署deepseek-R1-1.5b
安装conda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh bash ~/Miniconda3-latest-Linux-x86_64.sh source ~/.bashrc
在deepseek官方文档(https://github.com/deepseek-ai/DeepSeek-V3)中注意到:

创建环境
conda create -n deepseek python=3.10 conda activate deepseek
安装pytorch
终端中输入以下代码查看本机GPU支持的cuda版本:
nvidia-smi
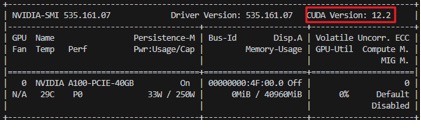
因此,我们需要的pytorch版本是:**版本号为****2.4.1**且**CUDA<=12.2**的版本
前往 https://pytorch.org/get-started/previous-versions/安装满足本机的版本:
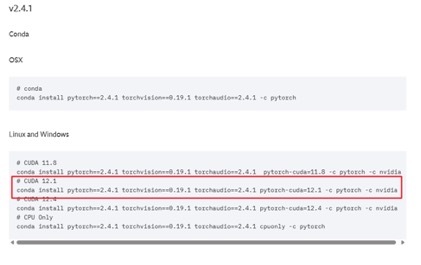
复制代码至终端并执行即可
conda install pytorch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 pytorch-cuda=12.1 -c pytorch -c nvidia
如果下载速度慢,可以输入以下命令添加国内源:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
安装剩余依赖项
pip install triton==3.0.0 transformers==4.46.3 safetensors==0.4.5 accelerate==1.4.0
下载模型文件
https://www.modelscope.cn/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
魔搭社区(modelscope)是一个国内的模型库,比起huggingface能提供更稳定的下载
pip install modelscope modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --local_dir your/path
编写推理代码
导入所需的类,AutoModelForCausalLM用于加载因果语言模型,AutoTokenizer用于文本标记化
from transformers import AutoModelForCausalLM, AutoTokenizer
指定预训练模型的路径
model_name = "/your/path/to/deepseek-R1-1.5B"
从预训练模型加载语言模型
torch_dtype="auto"表示自动选择合适的数据类型
device_map="auto"表示自动将模型分配到可用的设备上(如GPU或CPU)
model.eval() 将模型设为评估模式,节省显存。
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
model.eval()
加载与模型对应的分词器
tokenizer = AutoTokenizer.from_pretrained(model_name)
定义用户输入的提示文本
prompt = "请简单介绍一下你自己。"
创建消息列表,包含系统消息和用户消息
messages = [
{"role": "system", "content": "你是一个智能助手,擅长用中文回答用户的提问。"},
{"role": "user", "content": prompt}
]
应用聊天模板将消息格式化为模型可接受的格式
tokenize=False表示不进行标记化,返回文本字符串
add_generation_prompt=True表示添加生成提示标记
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
将格式化后的文本转换为模型输入的张量,并移至模型所在的设备
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
使用模型生成回复
max_new_tokens=1024 表示限制生成的最大token数为1024
generated_ids = model.generate(
**model_inputs,
max_new_token = 1024
)
从生成的ID中提取新生成的部分(去除输入部分)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
将生成的ID解码为文本,skip_special_tokens=True表示跳过特殊标记
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
打印模型的回复
print(response)

扩展
自定义输出风格
在model.generate中可设置超参数:
其中,temperature和top_p是两种不同的控制生成内容随机性的超参数,将这两个参数设置得越低,会得到越稳定保守的结果,反之则会得到更多样和创造性的输出。
repetition_penalty用于减少文本中的重复内容。值大于1时,会降低已经生成过的词汇再次被选中的概率。
通常,建议将取值控制在以下范围:
- temperature:0 - 1.5
- top_p: 0.7 - 0.9
- repetition_penalty: 1 - 1.3
generated_ids = model.generate(
**model_inputs,
max_new_tokens=1024,
temperature = 0.7,
top_p = 0.8,
repetition_penalty = 1.1
)
完整代码:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "/home/sunyifan/deepseek-R1-1.5B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "请简单介绍一下你自己。"
messages = [
{"role": "system", "content": "你是一个智能助手,擅长用中文回答用户的提问。"},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512,
temperature = 0.7,
top_p = 0.8,
repetition_penalty = 1.1
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
多轮对话
要实现多轮对话能力,需要保存之前的对话内容
history, response = [], ""
将对话历史保存并加入到messages中
query = input("请输入内容:")
messages = [{"role": "system", "content": "你是一个智能助手,擅长用中文回答用户的提问。"}]
while query:
for query_h, response_h in history:
messages.append({"role": "user", "content": query_h})
messages.append({"role": "assistant", "content": response_h})
messages.append({"role": "user", "content": query})
... #对话响应代码
history.append([query, response])
query = input("请输入内容:")


完整代码:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "/home/sunyifan/deepseek-R1-1.5B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
history, response = [], ""
query = input("请输入内容:")
messages = [{"role": "system", "content": "你是一个智能助手,擅长用中文回答用户的提问。"}]
while query:
for query_h, response_h in history:
messages.append({"role": "user", "content": query_h})
messages.append({"role": "assistant", "content": response_h})
messages.append({"role": "user", "content": query})
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=1024,
temperature = 0.7,
top_p = 0.8,
repetition_penalty=1.1
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
history.append([query, response])
query = input("请输入内容:")
实验二:用Gradio快速制作web页面
尽管我们成功地把大模型部署到了本地,但使用命令行的交互方式让人很不舒服,所以我们可以制作一个web页面来跟大模型对话。
Gradio 是专为机器学习模型设计的 Web 界面制作工具。
首先下载Gradio:
pip install Gradio
在我们之前写的py文件中,将生成回复写成一个函数并略微修改历史对话记忆,让其符合gradio的格式
def generate_response(message, history, temperature=0.6, top_p=0.95, max_length=1024, repetition_penalty=1.1):
messages = [{"role": "system", "content": "你是一个智能助手,擅长用中文回答用户的提问。"}]
for h in history:
messages.append({"role": "user", "content": h[0]}) # 添加用户的历史消息
messages.append({"role": "assistant", "content": h[1]}) # 添加助手的历史回复
messages.append({"role": "user", "content": message})
如果不希望展示思考内容,添加以下代码段处理模型的生成结果
think_content = ""
if "</think>" in response:
parts = response.split("</think>", 1)
think_content = parts[0].strip()
if think_content.startswith("<think>"):
think_content = think_content[7:].strip()
response = parts[1].strip()
接下来,开始创建gradio界面
创建Blocks对象,这是Gradio的主要界面构建工具:
with gr.Blocks(css=".container { max-width: 800px; margin: auto; }") as demo:
添加各界面组件:
#创建标题
gr.HTML(
"""
<div style="text-align: center; max-width: 800px; margin: 0 auto;">
<div style="display: inline-flex; align-items: center; gap: 0.8rem; font-size: 1.75rem;">
<h1 style="font-weight: 900; margin-bottom: 7px; margin-top: 5px;">
DeepSeek 大模型聊天界面
</h1>
</div>
<p style="margin-bottom: 10px; font-size: 94%; line-height: 23px;">
基于DeepSeek-R1-1.5B模型的聊天应用
</p>
</div>
"""
)
with gr.Row(): # 创建行布局 with gr.Column(scale=4): # 创建列布局,scale=4表示占据4/5的宽度 # 创建聊天机器人组件 chatbot = gr.Chatbot( [], # 初始对话历史为空 elem_id="chatbot", height=600, # 设置高度 ) with gr.Row(): # 创建输入区域的行布局 with gr.Column(scale=8): # 输入框占8/9的宽度 # 创建文本输入框 msg = gr.Textbox( show_label=False, # 不显示标签 placeholder="请输入您的问题...", # 占位文本 container=False # 不显示容器边框 ) with gr.Column(scale=1): # 发送按钮占1/9的宽度 submit_btn = gr.Button("发送") # 创建发送按钮
with gr.Row(): clear_btn = gr.Button("清空对话") # 创建清空对话按钮
with gr.Column(scale=1): # 参数设置区域,占据1/5的宽度 with gr.Accordion("参数设置", open=True): # 创建可折叠的参数设置区域 # 创建各种参数的滑动条 temperature = gr.Slider( minimum=0.1, maximum=2.0, value=0.6, step=0.01, label="Temperature", info="控制生成文本的随机性" ) top_p = gr.Slider( minimum=0.5, maximum=1.0, value=0.95, step=0.05, label="Top P", info="控制生成文本的多样性" ) max_length = gr.Slider( minimum=256, maximum=10240, value=1024, step=128, label="最大生成长度" ) repetition_penalty = gr.Slider( minimum=1.0, maximum=1.5, value=1.1, step=0.05, label="重复惩罚系数", info="控制生成文本的重复度" )
创建事件处理函数:
def clear_history():
return None
def respond(message, chat_history, temp, p, length, penalty):
chat_history = chat_history + [[message, None]]
user_message = chat_history[-1][0]
print("temp:", temp)
bot_message, _ = generate_response(
user_message,
chat_history[:-1],
temperature=temp,
top_p=p,
max_length=length,
repetition_penalty=penalty
)
chat_history[-1][1] = bot_message
return "", chat_history
创建事件监听器:
\#当用户回车时执行respond函数
msg.submit(
respond,
[msg, chatbot, temperature, top_p, max_length, repetition_penalty],
[msg, chatbot]
)
\#当用户点击submit按钮时执行respond函数
submit_btn.click(
respond,
[msg, chatbot, temperature, top_p, max_length, repetition_penalty],
[msg, chatbot]
)
\#当用户点击clear按钮时执行clear_history函数
clear_btn.click(clear_history, None, chatbot, queue=False)
启动Gradio应用
if __name__ == "__main__":
demo.queue() # 启用队列功能,用于处理并发请求
demo.launch(share=False, inbrowser=True) # 启动应用,不分享公开链接,自动打开浏览器