基础
前言
监控是基础设施,目的是为了解决问题,不要只朝着大而全去做,尤其是不必要的指标采集,浪费 人力和存储资源(To B商业产品例外)。
需要处理的告警才发出来,发出来的告警必须得到处理。
简单的架构就是最好的架构,业务系统都挂了,监控也不能挂。Google Sre 里面也说避免使用 Magic 系统,例如机器学习报警阈值、自动修复之类。这一点见仁见智吧,感觉很多公司都在搞智 能 AI 运维。
局限性
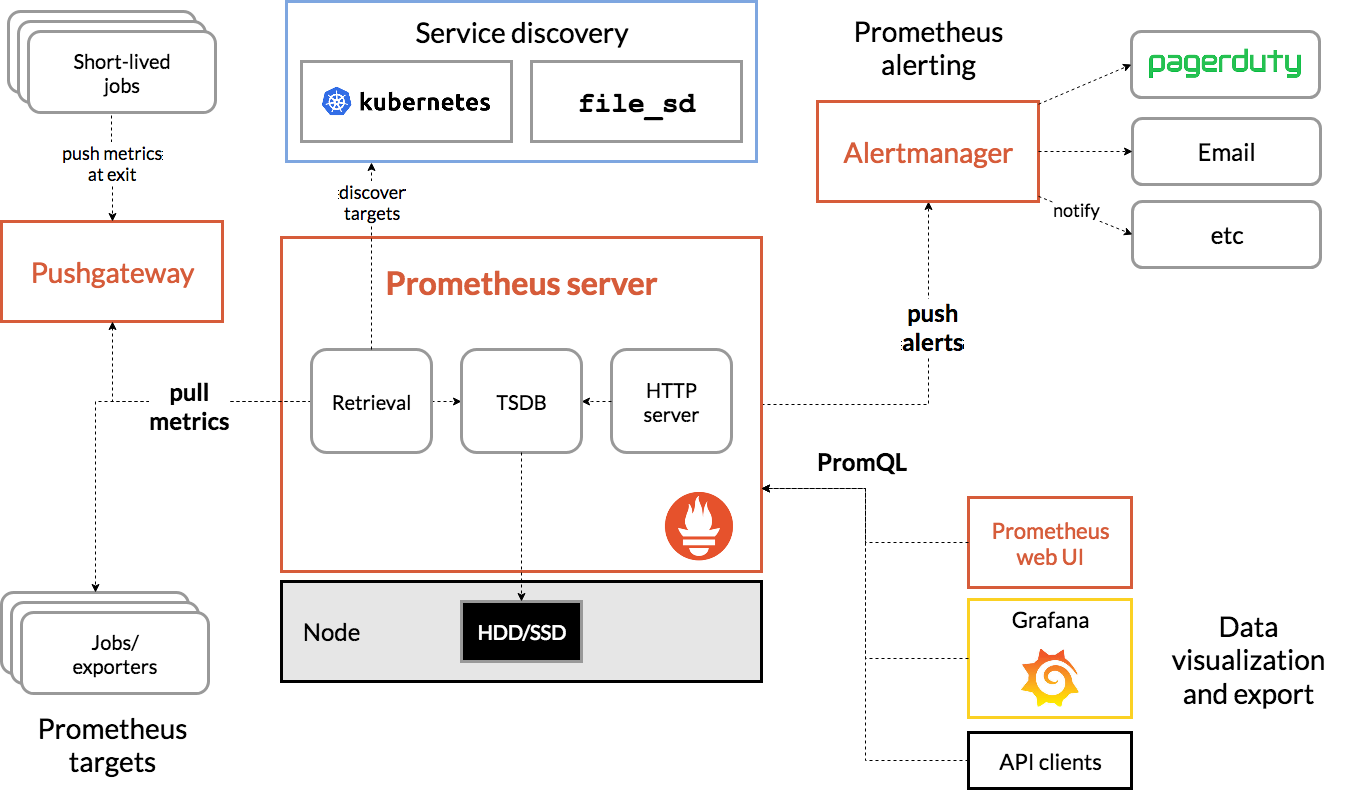
Prometheus 是基于 Metric 的监控,不适用于日志(Logs)、事件(Event)、调用链(Tracing)。 Prometheus 默认是 Pull 模型,合理规划你的网络,尽量不要转发。
对于集群化和水平扩展,官方和社区都没有银弹,需要合理选择 Federate、Cortex、Thanos等方 案。 监控系统一般情况下可用性大于一致性,容忍部分副本数据丢失,保证查询请求成功。这个后面说 Thanos 去重的时候会提到。
Prometheus 不一定保证数据准确,这里的不准确一是指 rate、histogram_quantile 等函数会做 统计和推断,产生一些反直觉的结果,这个后面会详细展开。二来查询范围过长要做降采样,势必 会造成数据精度丢失,不过这是时序数据的特点,也是不同于日志系统的地方。
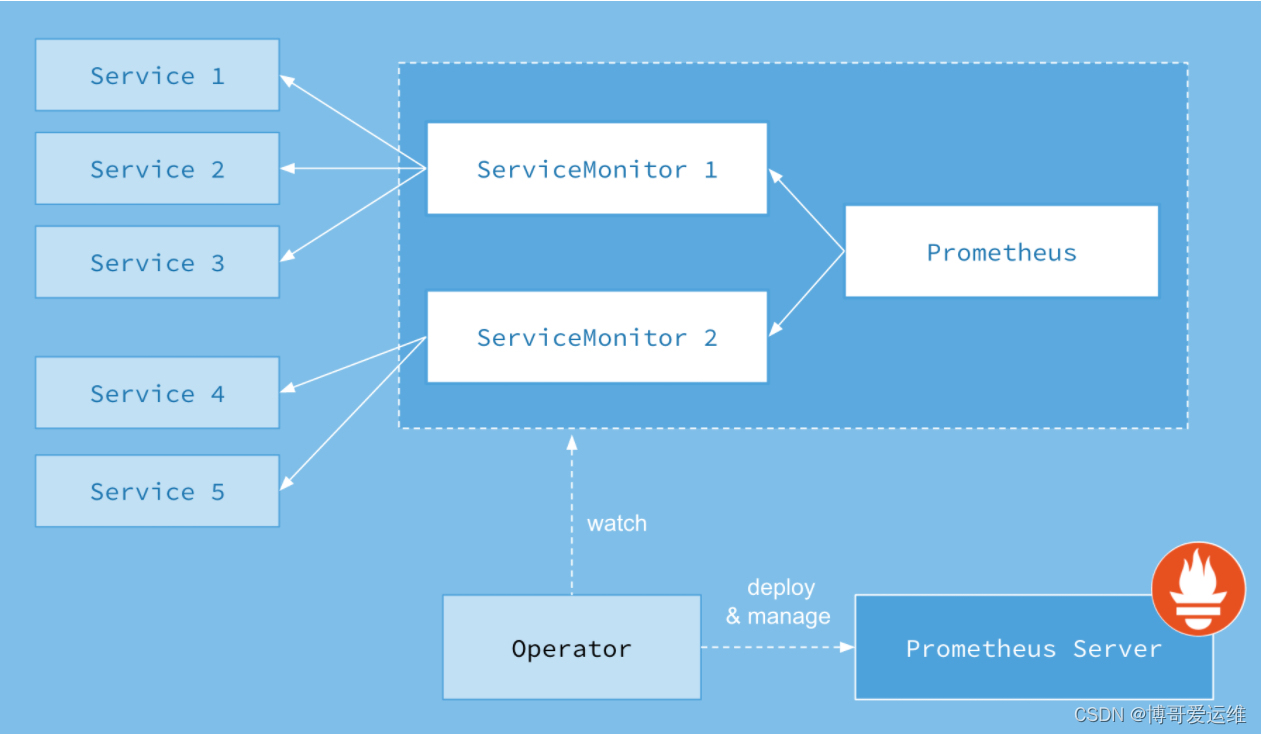
operator 局限性
因为是 operator,所以依赖 K8S 集群,如果你需要二进制部署你的 Prometheus,如集群外部 署,就很难用上prometheus-operator了,如多集群场景。当然你也可以在 K8S 集群中部署 operator 去监控其他的 K8S 集群,但这里面坑不少,需要修改一些配置。 operator 屏蔽了太多细节,这个对用户是好事,但对于理解 Prometheus 架构就有些 gap 了,比 如碰到一些用户一键安装了operator,但 Grafana 图表异常后完全不知道如何排查,record rule 和 服务发现还不了解的情况下就直接配置,建议在使用 operator 之前,最好熟悉 prometheus 的 基础用法。
operator 方便了 Prometheus 的扩展和配置,对于 alertmanager 和 exporter 可以很方便的做到 多实例高可用,但是没有解决 Prometheus 的高可用问题,因为无法处理数据不一致,operator 目前的定位也还不是这个方向,和 Thanos、Cortex 等方案的定位是不同的,下面会详细解释。
exporter
cadvisor: 集成在 Kubelet 中。 kubelet: 10255为非认证端口,10250为认证端口。 apiserver: 6443端口,关心请求数、延迟等。 scheduler: 10251端口。 controller-manager: 10252端口。 etcd: 如etcd 写入读取延迟、存储容量等。 docker: 需要开启 experimental 实验特性,配置 metrics-addr,如容器创建耗时等指标。 kube-proxy: 默认 127 暴露,10249端口。外部采集时可以修改为 0.0.0.0 监听,会暴露:写入 iptables 规则的耗时等指标。 kube-state-metrics: K8S 官方项目,采集pod、deployment等资源的元信息。 node-exporter: Prometheus 官方项目,采集机器指标如 CPU、内存、磁盘。 blackbox_exporter: Prometheus 官方项目,网络探测,dns、ping、http监控 process-exporter: 采集进程指标 nvidia exporter: 我们有 gpu 任务,需要 gpu 数据监控 node-problem-detector: 即 npd,准确的说不是 exporter,但也会监测机器状态,上报节点异常 打 taint 应用层 exporter: mysql、nginx、mq等,看业务需求。
Prometheus 体系中 Exporter 都是独立的,每个组件各司其职,如机器资源用 Node-Exporter,Gpu 有Nvidia Exporter等等。但是 Exporter 越多,运维压力越大,尤其是对 Agent做资源控制、版本升 级。我们尝试对一些Exporter进行组合,方案有二:
- 通过主进程拉起N个 Exporter 进程,仍然可以跟着社区版本做更新、bug fix。
- 用Telegraf来支持各种类型的 Input,N 合 1。
另外,Node-Exporter 不支持进程监控,可以加一个Process-Exporter,也可以用上边提到的 Telegraf,使用 procstat 的 input来采集进程指标
黄金指标
延迟、流 量、错误数、饱和度
Use 用于资源,Red 用于服务。
Use 方法:Utilization(利用�率)、Saturation(饱和)、Errors。如 Cadvisor 数据
Red 方法:Rate(率)、Errors、Duration(持续时间)。如 Apiserver 性能指标
Prometheus 采集中常见的服务分三种:
-
在线服务:如 Web 服务、数据库等,一般关心请求速率,延迟和错误率即 RED 方法
-
离线服务:如日志处理、消息队列等,一般关注队列数量、进行中的数量,处理速度以及发生的错误即 Use 方法
-
批处理任务:和离线任务很像,但是离线任务是长期运行的,批处理任务是按计划运行的,如持续
集成就是批处理任务,对应 K8S 中的 job 或 cronjob, 一般关注所花的时间、错误数等,因为运 行周期短,很可能还没采集到就运行结束了,所以一般使用 Pushgateway,改拉为推。
对 Apiserver 的性能影响
如果你的 Prometheus 使用了 kubernetes_sd_config 做服务发现,请求一般会经过集群的 Apiserver, 随着规模的变大,需要评估下对 Apiserver性能的影响,尤其是Proxy失败的时候,会导致CPU 升高。当 然了,如果单K8S集群规模太大,一般都是拆分集群,不过随时监测下 Apiserver 的进程变化还是有必 要的。
在监控Cadvisor、Docker、Kube-Proxy 的 Metric 时,我们一开始选择从 Apiserver Proxy 到节点的对 应端口,统一设置比较方便,但后来还是改为了直接拉取节点,Apiserver 仅做服务发现。