大内存
Prometheus 大内存问题
随着规模变大,Prometheus 需要的 CPU 和内存都会升高,内存一般先达到瓶颈,这个时候要么加内 存,要么集群分片减少单机指标。这里我们先讨论单机版 Prometheus 的内存问题。
原因:
Prometheus 的内存消耗主要是因为每隔2小时做一个 Block 数据落盘,落盘之前所有数据都在内 存里面,因此和采集量有关。 加载历史数据时,是从磁盘到内存的,查询范围越大,内存越大。这里面有一定的优化空间。 一些不合理的查询条件也会加大内存,如 Group 或大范围 Rate。
我的指标需要多少内存:
作者给了一个计算器,设置指标量、采集间隔之类的,计算 Prometheus 需要的理论内存值:计算 公式
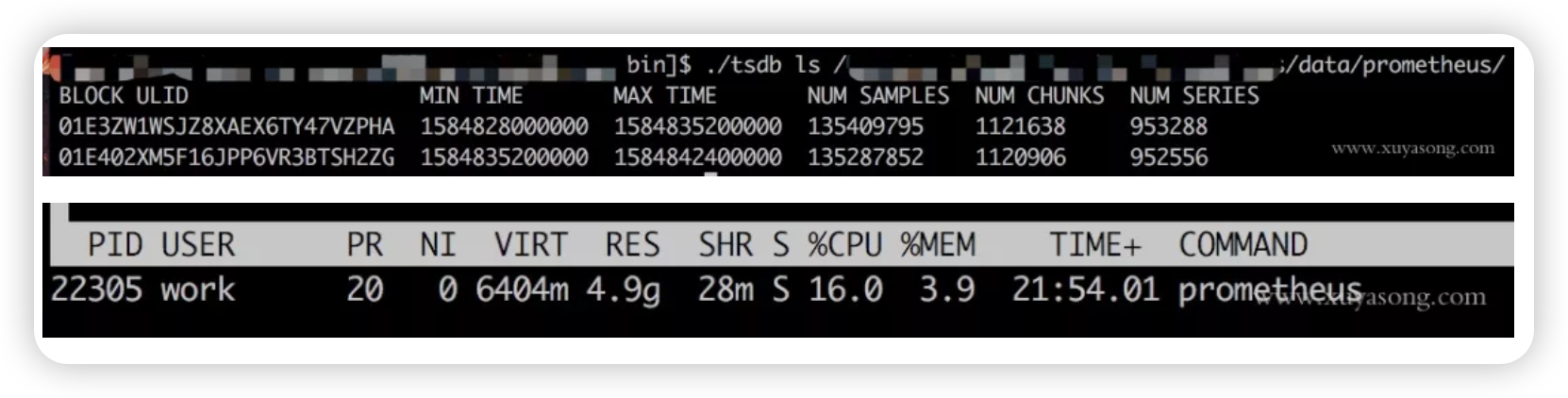
以我们的一个 Prometheus Server为例,本地只保留 2 小时数据,95 万 Series,大概占用的内存如 下:
有什么优化方案:
Sample 数量超过了 200 万,就不要单实例了,做下分片,然后通过 Victoriametrics,Thanos, Trickster 等方案合并数据。 评估哪些 Metric 和 Label 占用较多,去掉没用的指标。2.14 以上可以看 Tsdb 状态 查询时尽量避免大范围查询,注意时间范围和 Step 的比例,慎用 Group。 如果需要关联查询,先想想能不能通过 Relabel 的方式给原始数据多加个 Label,一条Sql 能查出 来的何必用Join,时序数据库不是关系数据库。
Prometheus 内存占用分析:
通过 pprof分析:https://www.robustperception.io/optimising-prometheus-2-6-0-memory-us age-with-pprof 1.X 版本的内存:https://www.robustperception.io/how-much-ram-does-my-prometheus-nee d-for-ingestion
相关 issue